Agents: Parallelisation and Management¶
Agents are the central concept of QHG simulations. They represent individuals, each carrying ‘personal’ attributes such as an ID, age, gender etc.
Parallelisation¶
In order to run simulations with a large number of agents (several 100’000) in reasonable time, it is necessary to use parallelisation. In QHG parallelization is mainly applied over agents, in some cases also over cells. In QHG, we use the OpenMP interface which provides shared memory parallelization.
The earlier versions of QHG used Open MPI (open source Message Passing Interface implementation) which allows you to distribute computations over several computers. However, simulations slowed down considerably when there were large numbers of agents. The slow-down was mainly due to the big overhead for message passing: whenever an agent moved from the domain of one computer to the domain of a neighboring one, its agent had to be sent from the origin to the target node, which is OK for small messages, but for simulations with several 10000 agentsthe overhead became to big.
The Agent Container¶
In early versions a naive implementation was used: Agents were defined as classes, and the simulation had an array (or vector) of agent instances.
Whenever an agent was born a new instance was created (with new) and inserted into the array, whenever anagent dies, it was removed from the array and destroyed(with delete).
This approach turned out to be a bad choice - profiling showed that most of the run time was used for agent creation and deletion.
The current implementation uses an array of structures instead of an array of instances.

Each of the structures represent the data of one agent. This setup allows easy parallelisation over agents.
The agent structures are defined in the header file of a population class (see SPopulations), which also holds the container for the agent structures,
In QHG tthis container is realized with a LayerBuf object, which, in essence, is a vector of agent arrays.
std::vector<T*> m_vUsedLayers;
Initially the vector is empty.
Whenever there is no more space to complete the addition of an agent, a new layer (i.e. agent array) is allocated and added to the vector. Empty arrays are not immediately deleted. If such an array exists it is added to the vector instead of a new one, thus avoiding the allocation of a new one
The LayerBuf holding the agents is controlled by a LBController, which has a L2List to control used and unused locations for each of its layers.

concrete implementation
Management¶
At any given time the cntainer has active locations (the ones currently in use) as well as passive locations (currently unused).
This setup requires some book-keeping. For this reason SPopulation has an LBController which controls the indexes of the active and passive array locations by means of 2 doubly linked lists (L2List).

Whenever a new agent needs to be added the index of the first passive location is moved to the active list and the new agents data is written to the corresponding position. Whenever an agent dies, the index of its location is moved from the active list to the passive list.
Moving a location from an unused to a used state requires several operations in the linked lists:
set
next.prevtothis.prev. Ifthisis the first element, setnext.prevtonilset
prev.nexttothis.next. Ifthisis the last element, setprev.nexttonil.if
thisis the first of the passive elements, setpassive.starttothis.next
This leaves the index of interest isolated.

Now find the highest active index less than the index of this (in our example: index 0).
If there is no such index:
set
this.nexttoactive.startset
active.starttothisset
this.prevtonil
Otherwise, i.e. there is such an index ‘last’:
set
this.nexttolast.nextset
last.next.prevtothisset
last.nexttothisset
this.prevtolast

Moving a used location to passive state requires a similar set of operations. It is important to keep in mind that operations on the lists must not be parallelized. If several threads write to the lists at the same time, it would very probably end up in an undefined state.
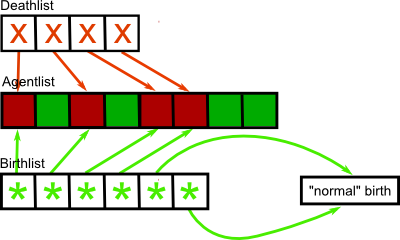
Dead Agent Recycling¶
To minimize list-operations during a simulation we use dead agent recycling. The indexes of agents who die during a simulation step are registered in a list. When new agents are born we place their data into the structures pointed at by the dead agents list. If more agents are born than have died, the surplus agents have to do a normal birth process: change a passive location to an active one and copy their data there. If there are less new agents than dead ones, the left over locations are carried over to the next step’s dead agent list.